AI大语言模型 (Artificial Intelligence Large Language Model) • AI (Artificial Intelligence): 人工智能。这部分表明了AI的本质——不是一个真实的人类,而是通过计算机程序和算法构建出来的智能体。能够执行通常需要人类智能才能完成的任务,比如学习、推理、解决问题、理解语言等等。 • 大 (Large): 大型。这个词描述了模型的规模。AI通过学习海量的文本数据(例如书籍、文章、网站内容等)来获得知识和能力。 “大型”意味着模型拥有庞大的参数数量(可以理解为神经元之间的连接),这使得AI模型能够处理和生成复杂的语言模式。 • 语言 (Language): 语言。这表明了我的主要功能和应用领域。我专注于理解和生成人类语言。我可以阅读、写作、翻译、总结文本,并与人类进行对话。 • 模型 (Model): 模型。这个词指的是我的构建方式。我是一个基于数学和统计学的模型。更具体地说,我通常是基于一种叫做“Transformer”的深度学习架构。这个模型通过分析大量文本数据中的统计规律,来学习词语之间的关系、句子的结构以及语言的整体模式。 所以“AI大语言模型”可以看成 是一种基于数学和算法构建的、用于执行特定人工智能任务的结构。它本质上是由大量的参数、算法和数据组成的复杂系统。 整体架构:Transformer 目前主流的大语言模型大多基于Transformer架构。Transformer的核心思想是“自注意力机制”(Self-Attention Mechanism),这使得模型能够捕捉文本序列中不同词语之间的关系,无论这些词语在句子中的距离有多远。 核心组件:层(Layers) Transformer模型是由多个相同的“层”(Layer)堆叠而成的。每个层都包含以下几个关键子组件: 自注意力层(Self-Attention Layer): 这是Transformer的核心。它允许模型关注输入序列中不同位置的信息,并计算它们之间的关系。 从线性代数的角度来看,自注意力机制可以看作是对输入序列进行一系列线性变换(矩阵乘法),然后通过Softmax函数进行归一化,得到注意力权重。这些权重表示不同位置之间的相关性。 前馈神经网络层(Feed-Forward Neural Network Layer): 在自注意力层之后,每个位置的表示都会通过一个前馈神经网络进行处理。 这个前馈网络通常包含两个线性变换(矩阵乘法)和一个激活函数(如ReLU)。 残差连接(Residual Connections): 在每个子层(自注意力层和前馈网络层)周围都有一个残差连接。 这意味着子层的输入会直接加到子层的输出上。这有助于缓解深度神经网络中的梯度消失问题,使得模型更容易训练。 层归一化(Layer Normalization): 在每个子层之后,都会应用层归一化。 层归一化有助于稳定训练过程,并提高模型的性能。它会对每个样本在层的维度上进行归一化。 基本组成单元:神经元(Neurons) 无论是自注意力层还是前馈神经网络层,它们都是由大量的“神经元”组成的。每个神经元可以看作是一个简单的计算单元。 总结一下: 从最底层到最高层,模型的构成可以这样理解: 神经元:执行基本计算单元(加权求和、激活函数)。 层:由多个神经元组成,包括自注意力层和前馈神经网络层,以及残差连接和层归一化。 Transformer架构:由多个层堆叠而成,利用自注意力机制捕捉文本序列中的长距离依赖关系。 参数:模型的权重和偏置,通过学习数据来调整。比如deepseek参数最大的是671B. 层的概念什么是“层”?你可以把“层”想象成一个信息处理的“工序”或者“步骤”。每一层都接收一些输入信息,然后对这些信息进行特定的处理和转换,最后输出处理后的信息给下一层。 就像工厂里的流水线一样: 原材料:最初的输入文本(比如一个句子)。 第一道工序(第一层):比如,把每个单词转换成一个数字表示(词嵌入)。 第二道工序(第二层):比如,分析每个单词和句子中其他单词的关系(自注意力机制)。 第三道工序(第三层):比如,根据单词之间的关系,进一步理解整个句子的含义。 … 更多工序(更多层):每一层都在前一层的基础上进行更深层次的处理。 最终产品:模型对输入文本的最终理解(比如,判断这句话的情感是积极还是消极)。 为什么需要“多层”?为什么要这么多层,而不是一层搞定呢? 逐步抽象:每一层都在前一层的基础上进行更抽象的表示。 第一层可能关注的是单词的含义。 第二层可能关注的是词组的含义。 第三层可能关注的是句子的含义。 … 更深层可能关注的是段落、篇章的含义。 举个例子:图像识别 虽然我们主要讨论的是语言模型,但“层”的概念在图像识别中也非常常见,而且更容易可视化理解。 想象一下,一个用于识别猫的图像的神经网络: 输入:一张猫的图片(可以看作是一个像素矩阵)。 第一层:可能检测图像中的简单边缘和纹理。 第二层:可能将边缘和纹理组合成更复杂的形状,比如猫的耳朵、眼睛的轮廓。 第三层:可能将这些形状组合成猫的脸部特征。 第四层:可能根据脸部特征识别出这是一只猫。 每一层都在前一层的基础上提取更高级别的特征。 回到语言模型在语言模型中,层的工作方式类似,但处理的是文本而不是图像: 输入:“The cat sat on the mat.” 第一层(词嵌入层): “The” -> [0.1, 0.2, 0.3] “cat” -> [0.4, 0.5, 0.6] “sat” -> [0.7, 0.8, 0.9] … (每个单词被转换成一个向量) 第二层(自注意力层): 计算每个单词与其他单词之间的关系。 比如,”sat” 这个词可能与 “cat” 和 “mat” 有更强的关系。 第三层(前馈网络层): 对每个单词的表示进行进一步处理。 … 更多层: 每一层都在前一层的基础上进行更深层次的理解。 最后一层: 可能输出模型对整个句子的理解,或者预测下一个单词(比如 “.”), 或者进行情感分类等任务。
好,现在有了这些基础知识,我们正式进入主题,AI大模型是怎么理解一句话的? 在回答这个问题之前,我们先来想一个问题,AI能从字面意义上理解人类的话吗?它真的知道苹果是什么东西吗?这个我想很多人都会回答不能。答案也确实是不能,很明显,目前的AI的发展还处于初级阶段,能力还没有达到这种地步。 不信的可以那下面一段对话也考一考AI
笔者拿了市面上比较知名的10款AI,其中还包括deepseekR1,Claude等知名大模型。结果是没有一个模型能够判断”再等一等也没有了“这句话断句方式是这样的:再等/一等/也没有了。所有的模型都是这样断句的,再/等一等/也没有了。可以说是全军覆没。 因此现阶段AI尚且不能从字母意义上理解,那它们是怎么理解的呢?这还的从AI大模型的本质上来说。开头我们就介绍了,模型本质是数学和算法的结合体。它实际上就算数学的应用,所以它只能从数学的角度理解一句话。这就是词嵌入——语言的数字化。 当我们在模型中输入一句话时,比如”The cat sat on the mat.” 首先这句话会被分割成一个一个token,每个token,都对应着一个向量。 – 第一层(词嵌入层): – “The” -> [0.1, 0.2, 0.3] – “cat” -> [0.4, 0.5, 0.6] – “sat” -> [0.7, 0.8, 0.9] – … – (每个单词被转换成一个向量) 所以输入的一句话会被转化成矩阵,即语言的数字化 上述过程称为词嵌入,对应的向量称为词嵌入向量。所有嵌入向量组成的矩阵称为词嵌入矩阵。 词嵌入(Word Embedding)中的向量数值不是随意指定的,而是通过学习得到的。详细解释一下: 词嵌入的目标是:将词汇表中的每个词(token)映射到一个固定维度的向量空间中, 使得: •语义相似的词,对应的向量在空间中距离较近。 例如,“king” 和 “queen” 的向量应该比较接近。 •语义相关的词,向量之间存在一定的关系。 例如,“king” – “man” + “woman” 的结果向量应该与 “queen” 的向量比较接近(经典的“国王-男人+女人=女王”的例子)。 词嵌入矩阵不具备唯一性 在初始词嵌入时,同一句话里的相同的字对应的词嵌入向量不一定相同 词嵌入(Word Embedding)中的向量数值确实不是随意指定的,而是通过学习得到的。详细解释一下: 目标: •语义相似的词,对应的向量在空间中距离较近。 例如,“king” 和 “queen” 的向量应该比较接近。 •语义相关的词,向量之间存在一定的关系。 例如,“king” – “man” + “woman” 的结果向量应该与 “queen” 的向量比较接近(经典的“国王-男人+女人=女王”的例子)。 自注意力机制的计算步骤假设我们的输入序列是:”The cat sat on the mat.” 并且每个词已经通过词嵌入层转换成了向量。 转换成嵌入向量后,模型会创建一个位置编码向量。这个位置编码(Positional Encoding) 的核心目的是向 Transformer 模型提供输入序列中单词的位置信息,它蕴含了token之间的位置关系。 步骤 1: 计算 Query, Key, Value。 对于输入序列中的每个词,我们都计算三个向量: Query (Q): 查询向量。可以理解为“我需要关注什么?” Key (K): 键向量。可以理解为“我有什么信息可以提供?” Value (V): 值向量。可以理解为“我提供的具体信息是什么?”◦ 这三个向量是通过将每个词的词嵌入向量与三个不同的权重矩阵(WQ, WK, WV)相乘得到的。这些权重矩阵是模型需要学习的参数。 线性代数表示: 假设词嵌入向量的维度是 m。 WQ, WK, WV 的维度都是 m × m。(实际上,为了提高效率,通常会使用多头注意力机制,将 dmodel 分成多个头,每个头的维度是 dk = dmodel / h,其中 h 是头的数量。这里为了简化,我们先不考虑多头注意力。) 对于每个词 i: Qi = Wi * WQ Ki = Wi * WK Vi = Wi * WV (其中 Wi 是词 i 的词嵌入向量)
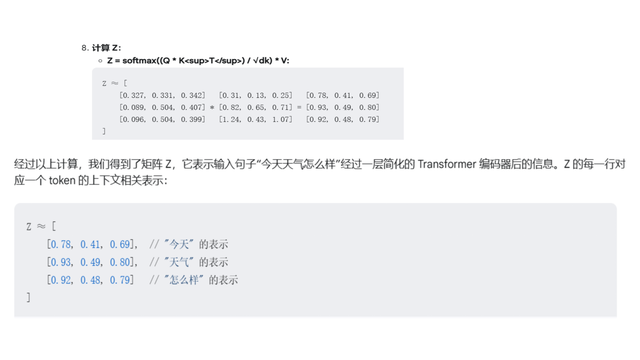
接下来我将用Gemini2.0模拟AI将这句话数据化的过程 注意: 为了便于演示和计算, 我会进行以下简化: • 嵌入向量维度 (dmodel): 3 维 • 头的数量 (h): 1 (我们只考虑单头注意力) • Q, K, V 维度 (dk): 3 维 (因为 h=1, 所以 dk = dmodel) • 不包含: ◦ 多头注意力机制 (只使用一个头) ◦ 前馈神经网络 ◦ 层归一化 ◦ 残差连接 ◦ 多层堆叠 (只计算一层) 步骤一: 1. 分词: 将句子“今天天气怎么样”分词为: [“今天”, “天气”, “怎么样”] 2. 嵌入向量(假设): “今天”: [0.1, 0.2, 0.3] “天气”: [0.4, 0.5, 0.6] “怎么样”: [0.7, 0.8, 0.9] 3.我们假设位置编码如下(3 维): 位置 0: [0.0, 0.0, 0.0] 位置 1: [0.8, 0.6, 0.0] 位置 2: [0.9, -0.4, 0.0] 4.输入表示: 将嵌入向量和位置编码相加,得到每个 token 的输入表示: “今天”: [0.1, 0.2, 0.3] + [0.0, 0.0, 0.0] = [0.1, 0.2, 0.3] “天气”: [0.4, 0.5, 0.6] + [0.8, 0.6, 0.0] = [1.2, 1.1, 0.6] “怎么样”: [0.7, 0.8, 0.9] + [0.9, -0.4, 0.0] = [1.6, 0.4, 0.9] 5.权重矩阵 (假设):
本文由 @yan 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务 |