当AI开口说话时,机器在思考什么? 凌晨三点的服务器机房,数以万计的显卡矩阵在黑暗中闪烁着幽蓝微光,神经网络中奔涌着每秒数万亿次的矩阵运算。当ChatGPT为你写出一首精巧的俳句,当Comfy UI的工作流生成令人惊叹的数字艺术,这些看似充满”灵性”的创造行为背后,实则运行着一套精密如钟表般的机械逻辑。 当你仔细研究一下会发现,大模型并不是常人所想象的那么简单。 例如我们在用「Deepseek」充值API的时候会发现明确标注着“每百万token输入xx元“又或者说本地部署时候总能提到的「满血版」「32B」等。这些到底是什么东西呢? 接下来就让我这个自诩站在大模型前沿的作者带你揭开大模型的神秘面纱,带你揭秘大模型背后的秘密。 Chat的含义从23开始由于AI的井喷式爆发,导致市面上出现了数不过来的大模型,单说国内的大模型已经达到了百家以上,但细心的小伙伴会发现一个问题,就是大模型的网址域名里面会出现一个单词「Chat」
而Chat在大模型中的真实含义指的是模型具备的对话能力,即能够像人类一样进行自然流畅的交流 1)Chat=对话在大模型中,“Chat” 表示模型具备与用户进行多轮对话交互的能力。 这种对话不仅仅是简单的问答,而是能够理解上下文、记住对话历史,并做出自然、连贯的回应。 2)Chat 也代表模型的应用场景 比如 ChatGPT,“Chat” 就是强调它的主要功能是聊天和对话,而 GPT 是 “Generative Pre-trained Transformer”(生成式预训练变换模型)。
总结来说就是,在AI大模型中,Chat代表了模型的“对话交互能力”,让模型不仅能“生成文字”,还能与用户连贯且智能地交流,提升互动体验。 LLM又是什么?LLM是Large Language Model的缩写,意思是大型语言模型。在平时生活中习惯性叫缩写,「LLM」 1)核心特点
2)如何工作
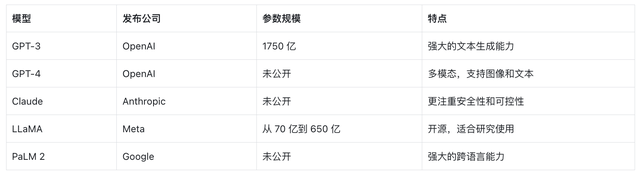
3)代表模型
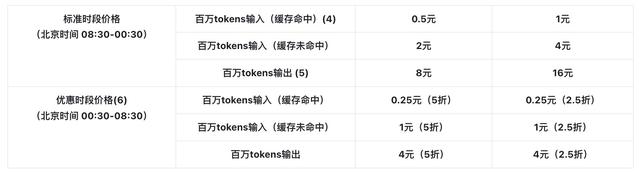
什么叫做Token在提到token的时候,很多人会不陌生,比如在使用用「Deepseek」充值API的时候会发现明确标注着“每百万token输入xx元,每百万输出tokenxxx元”。那这个token到底是什么东西呢,使用大模型所花的钱为什么要按照token计算呢。 下表为「Deepseek」的token计费方式。
1)Token的含义 在大模型中,Token(标记)是模型处理文本时的最小单位。大模型在训练和推理时,不是直接处理整段文字,而是将文本拆分成一系列的 Token,再进行分析和生成。 Token 是什么? Token ≠ 字符,Token 可以是一个字、一个词,甚至是词的一部分。 Token 的拆分方式依赖于模型所使用的分词算法,常见的有以下两种
2)token的计算方式标准是什么? token其实没有固定的字数限制,2个字可能是一个token、3个字可能是一个token、4个字也可能是一个token。 并且英文的token计算方式和中文的计算方式还不一样。 例: 英文句子 句子:ChatGPT is amazing! Token 拆分(按 BPE 算法可能是):[‘Chat’, ‘G’, ‘PT’, ‘ is’, ‘ amazing’, ‘!’] 英文中ChatGPT 被拆成了 ‘Chat’、’G’ 和 ‘PT’,is 和 amazing 也分别作为独立的 Token。 中文句子 句子:大模型很厉害。 Token 拆分(中文一般按字拆分):[‘大’, ‘模型’, ‘很’, ‘厉害’, ‘。’] 中文中,模型 和 厉害 可能会被作为整体 Token,也可能被拆开,取决于模型的训练数据。
经过本人的调研以及询问身边做AI的小伙伴来看一个普通人正常问一个问题大概在10-30个字之间。一个汉字算下来约等于0.6token,具体看汉字的复杂程度,最高是一个汉字一个token。上下聊天记录也算token,输出也算token 为什么 Token 重要?
大模型依靠什么计算token呢 上边提到大模型会把问题的字数分为不同token,那他是依靠什么来把字数分为不同token呢? 分词器 提到token就不得不提到一个东西那就是「分词器」 分词器(Tokenizer):是将自然语言文本拆分为 Token并将其映射为模型可理解的数字 ID的工具。 分词器和token关系
总结:分词器 = 把文本变成 Token 的工具,Token 是模型理解和处理的基本单元。分词器的效率和准确性,直接影响模型的性能和效果。
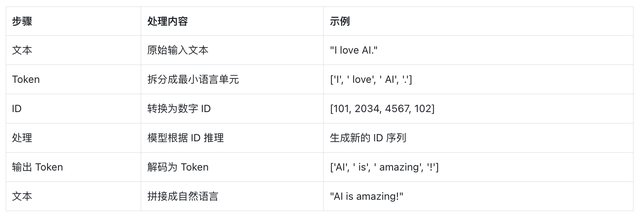
工作流程图 流程整体对比
蒸馏模型是什么?蒸馏模型(Knowledge Distillation Model)是一种模型压缩技术,通过将大型模型(教师模型,Teacher Model)的知识“转移”到一个更小、更轻量的模型(学生模型,Student Model),从而提升小模型的性能,同时减少其计算资源消耗。 通俗点解释就是在原有大模型基础上提取出来的小模型。Distill蒸馏意思,蒸馏出来的更小、清量、便捷。 为什么需要蒸馏模型?
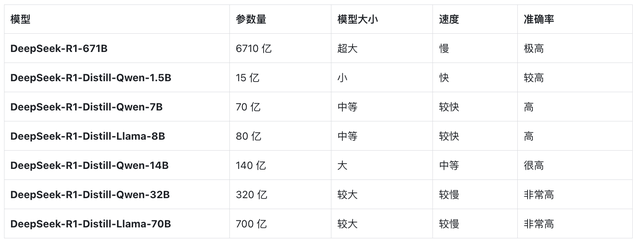
例子 :本地部署Deepseek-R1-(满血)671B → Deepseek-R1-Distil-70B
参数是什么?在大模型(如大型语言模型,LLM)中,参数(Parameters)是模型中可学习的权重值,用于定义模型如何处理和理解输入数据。 主要作用
举例
思维链是什么,为什么那么难?思维链(Chain of Thought,简称 CoT)是一种提升大模型推理能力的技术,指引模型在回答复杂问题时,逐步展示中间推理步骤,而不仅仅给出最终答案。 重要性 在传统的模型推理中,模型通常直接给出答案,但面对逻辑推理、数学计算、复杂问答等问题时,单步回答容易出错。 思维链通过引导模型分步骤思考,可以:
例子 : 问题:小明有 3 个苹果,他又买了 5 个苹果,然后吃掉了 2 个。请问他现在有多少个苹果? 普通回答:6 个。 思维链回答:
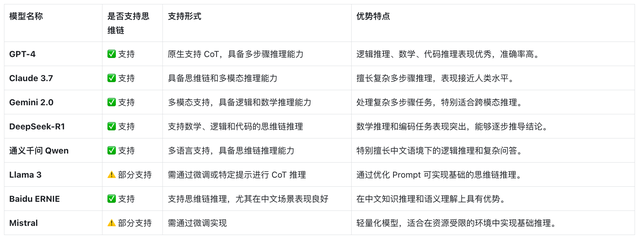
答案:6 个。 目前市面上支持思维链的模型有哪些
原生支持:如GPT-4、Claude 3、Gemini 1.5、DeepSeek-R1、通义千问,无需特别优化即可高效进行思维链推理。 部分支持:如Llama 2、Mistral,需要通过提示优化或额外训练才能实现高效的思维链推理。
结尾以上就是作者本人所了解到的大模型的知识,在这个AI时代,应该多了解一些AI的知识。 下期再见 本文由 @A ad钙 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自Unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务 |